Actions and Dynamics
Note
The action spaces are continuous for both teams, but can be wrapped into discrete settings (see Discrete Action Spaces).
Camera Actions
The camera supports rotation and zooming operations. The action of a camera is a pair of float numbers \((\Delta \phi, \Delta \theta)\) (in degrees). The input action will be clamped first:
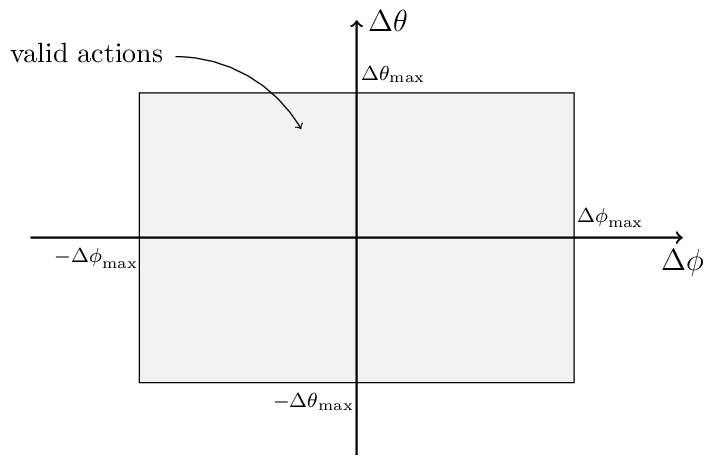
Camera’s Action Space
And the update rules for the camera at next timestep are:
The zoom in and out operations keep the area of the camera’s field of view, i.e., \(\frac{\pi}{360^{\circ}} \cdot \theta' \cdot {R_s'}^2 = \frac{\pi}{360^{\circ}} \cdot \theta_{\min} \cdot R_{s,\max}^2 = \text{constant}\).
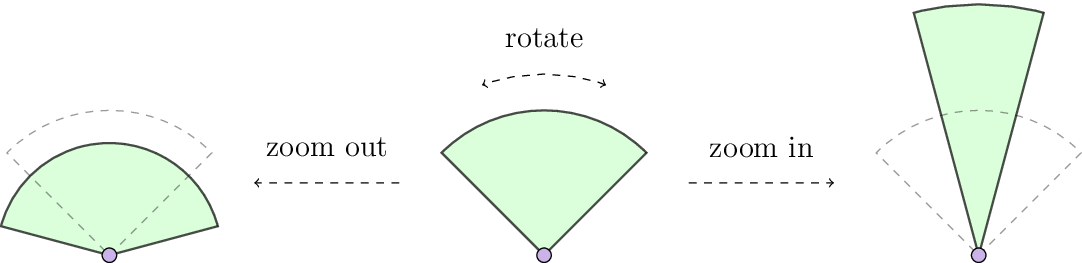
The area of the camera’s field of view is preserved.
The joint version of camera action is a 2D array, a stack of all cameras’ action. The shape of the joint action is \((N_{\mathcal{C}}, 2)\).
Target Actions
The action for targets is simple, a movement represented in cartesian coordinates. The input action \(\vec{\boldsymbol{v}} = (v_x, v_y)\) will be clamped first:
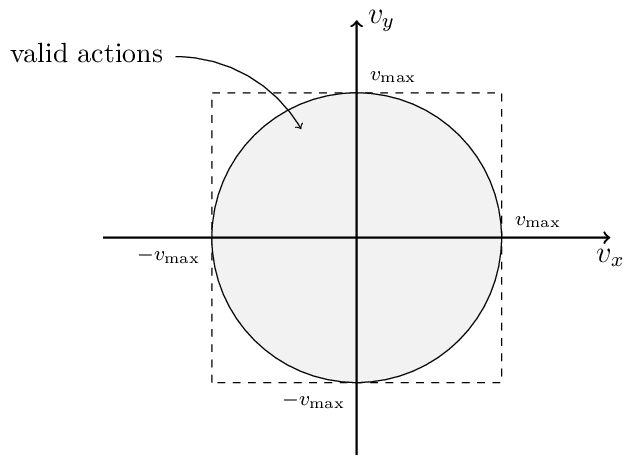
Target’s Action Space
Then if there are some obstacles in the target’s way. The action will be changed again:
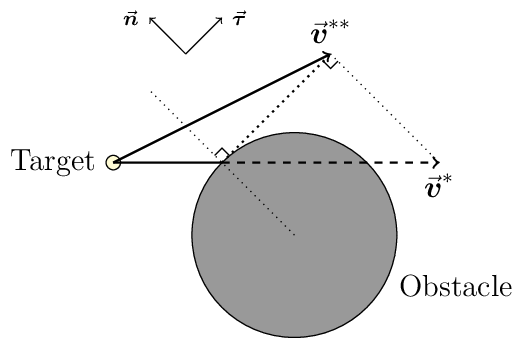
Collision Handling (keep the tangential component but drop the normal component after collision)
Finally, the update rules for the target at next timestep are:
The target’s coordinates will be clamped into the terrain space.
Note
The radiuses of targets are \(0\). Targets never collide with each other.
There is a circular barrier at the center of each camera, the collision rule treats this barrier as an obstacle.
In order to reduce the computational cost, the minimum distance between the obstacles is set to \(v_{\max}\), which means the target will never collide with more than one obstacle in a single step.
The obstacles never overlap the terrain boundary, and the target location will not be caught inside obstacles.
The joint version of target action is a 2D array, a stack of all targets’ action. The shape of the joint action is \((N_{\mathcal{T}}, 2)\).
- Related Resources