Built-in Wrappers
MATE provides multiple useful wrappers for different settings. Such as fully observability, discrete action spaces, single team multi-agent, etc.
Wrapper |
Description |
|
|---|---|---|
observation |
|
Enhance the agent’s observation, which sets all observation mask to |
|
Share field of view among agents in the same team, which applies the |
|
|
Add more environment and agent information to the |
|
|
Rescale all entity states in the observation to \([-1, +1]\). |
|
|
Convert all locations of other entities in the observation to relative coordinates. |
|
action |
|
Allow cameras to use discrete actions. |
|
Allow targets to use discrete actions. |
|
reward |
|
Add additional auxiliary rewards for each individual camera. |
|
Add additional auxiliary rewards for each individual target. |
|
single-team |
|
Wrap into a single-team multi-agent environment. |
|
||
|
Wrap into a single-team single-agent environment. |
|
|
||
communication |
|
Filter messages from agents of intra-team communications. |
|
Randomly drop messages in communication channels. |
|
|
Add a restricted communication range to channels. |
|
|
Disable intra-team communications, i.e., filter out all messages. |
|
|
Add extra message delays to communication channels. |
|
miscellaneous |
|
Repeat the |
You can create an environment with multiple wrappers at once. For example:
env = mate.make('MultiAgentTracking-v0',
wrappers=[
mate.EnhancedObservation,
mate.MoreTrainingInformation,
mate.WrapperSpec(mate.DiscreteCamera, levels=5),
mate.WrapperSpec(mate.MultiCamera, target_agent=mate.GreedyTargetAgent(seed=0)),
mate.RepeatedRewardIndividualDone,
mate.WrapperSpec(mate.AuxiliaryCameraRewards,
coefficients={'raw_reward': 1.0,
'coverage_rate': 1.0,
'soft_coverage_score': 1.0,
'baseline': -2.0}),
])
Repeated Reward and Individual Done
A wrapper that repeats the reward field and assigns individual done field of step(), which is similar to the OpenAI Multi-Agent Particle Environment (MPE).
(Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
base_env = mate.RepeatedRewardIndividualDone(base_env)
Enhanced Observation
A wrapper that enhances the agent’s observation, which sets all observation masks to True (see also Observations).
The targets can observe the empty status of all warehouses even when far away (see also Target States).
base_env = mate.make('MultiAgentTracking-v0')
enhance_both = mate.EnhancedObservation(base_env, team='both')
enhance_camera = mate.EnhancedObservation(base_env, team='camera')
enhance_target = mate.EnhancedObservation(base_env, team='target')
Note
The states of the opponents and teammates in the observation are still the public version.
Therefore, the observation output of this wrapper is not an exact full version of the environment.
For fully observable settings, please use env.state() instead.
More Training Information
A wrapper that adds more environment and agent information to the info field of step().
(Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
base_env = mate.MoreTrainingInformation(base_env)
This wrapper enables full observability for training and debugging. And that allows you to add auxiliary rewards and tasks to bypass the training problems caused by the sparse rewards and partial observations.
Note
This wrapper only adds more data into the info field and does not change the observation field.
Additional information for cameras:
coverage_ratereal_coverage_ratenum_trackedThe number of targets tracked by the current camera.
is_sensedA boolean value that indicates whether the current camera is sensed by any target or not.
Additional information for targets:
num_delivered_cargoesThe number of delivered cargoes.
goalThe index of the current target’s desired warehouse. If the current target holds no cargoes, this entry is set to
-1.goal_distanceThe distances from the current target and the desired warehouses. If the current target holds no cargoes, this entry is set to the half width of the terrain, i.e.,
mate.constants.TERRAIN_WIDTH / 2.0.warehouse_distancesAn \(N_{\mathcal{W}}\)-element array, which contains the distances between the current target and the warehouses.
individual_doneA boolean value that indicates whether the current target delivers the cargo to the desired warehouse (the mini-episode is done).
is_trackedA boolean value that indicates whether the current target is tracked by any camera or not.
is_collidingA boolean value that indicates whether the current target is colliding with obstacles, cameras’ barriers or the terrain boundary.
Enable the full observability for all agents (the true states of the environment):
stateAn 1D array of the global state of the environment.
camera_statesAn \(N_{\mathcal{C}} \times D_c^{\text{pvt}}\) matrix, which contains the private states of all cameras (see Camera States).
target_statesAn \(N_{\mathcal{T}} \times D_t^{\text{pvt}}\) matrix, which contains the private states of all targets (see Target States).
obstacle_statesAn \(N_{\mathcal{O}} \times D_o\) matrix, which contains the states of all obstacles (see Obstacle States).
camera_target_view_maskAn \(N_{\mathcal{C}} \times N_{\mathcal{T}}\) matrix, which contains the values of \(\operatorname{flag}^{(\text{C2T})} (c, t)\) (see Camera Observations).
camera_obstacle_view_maskAn \(N_{\mathcal{C}} \times N_{\mathcal{O}}\) matrix, which contains the values of \(\operatorname{flag}^{(\text{C2O})} (c, o)\) (see Camera Observations).
target_camera_view_maskAn \(N_{\mathcal{T}} \times N_{\mathcal{C}}\) matrix, which contains the values of \(\operatorname{flag}^{(\text{T2C})} (t, c)\) (see Target Observations).
target_obstacle_view_maskAn \(N_{\mathcal{T}} \times N_{\mathcal{O}}\) matrix, which contains the values of \(\operatorname{flag}^{(\text{T2O})} (t, o)\) (see Target Observations).
target_target_view_maskAn \(N_{\mathcal{T}} \times N_{\mathcal{T}}\) matrix, which contains the values of \(\operatorname{flag}^{(\text{T2T})} (t_1, t_2)\) (see Target Observations).
remaining_cargoesAn \(N_{\mathcal{W}} \times N_{\mathcal{W}}\) matrix, which contains the remaining number of cargoes to transport.
remaining_cargo_countsAn \(N_{\mathcal{W}}\)-element array, which contains the remaining number of cargoes to transport at the warehouses.
awaiting_cargo_countsAn \(N_{\mathcal{W}}\)-element array, which contains the awaiting number of cargoes to be delivered at the warehouses.
Relative Coordinates
A wrapper that converts all locations of other entities in the observation to relative coordinates (exclude the current agent itself). (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
base_env = mate.RelativeCoordinates(base_env)
Rescaled Observation
A wrapper that rescales all entity states in the observation to \([-1, +1]\). (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
base_env = mate.RescaledObservation(base_env)
Discrete Action Spaces
Action wrappers for discrete action space settings (see Actions and Dynamics):
base_env = mate.make('MultiAgentTracking-v0')
# assert levels >= 3 and levels % 2 == 1
discrete_camera = mate.DiscreteCamera(base_env, levels=5) # 25 discrete actions
discrete_target = mate.DiscreteTarget(base_env, levels=5) # 25 discrete actions
discrete_both = mate.DiscreteTarget(discrete_camera, levels=5) # 25 discrete actions
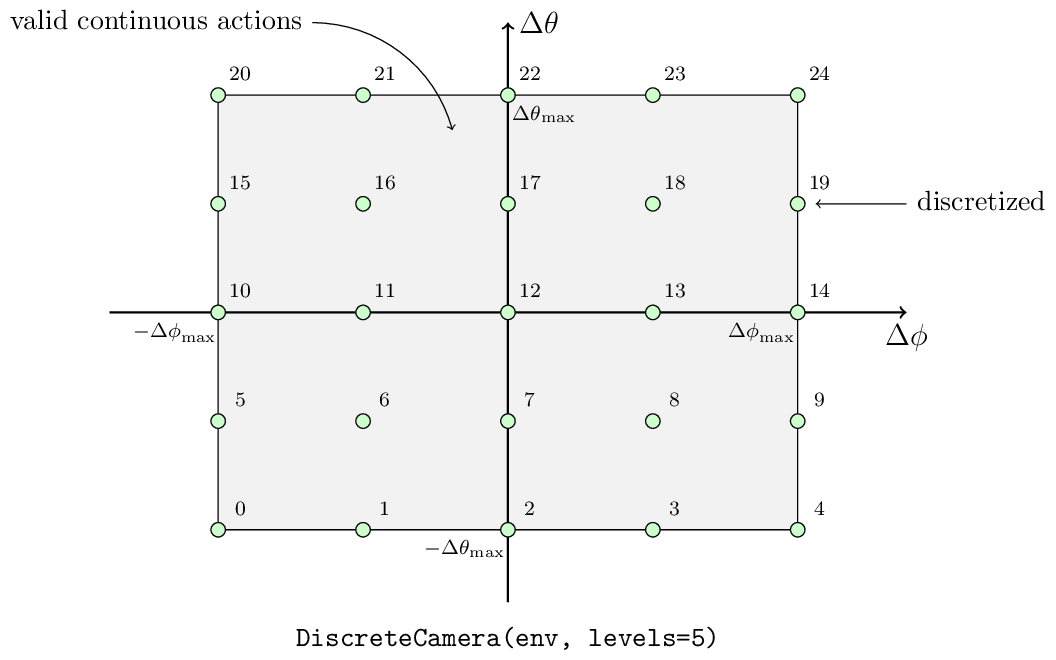
Discretization rule for cameras:
where \(i, j \in \{0, 1, \dots, n - 1\}\), and \(\xi = \frac{2 i}{n - 1} - 1\), and \(\eta = \frac{2 j}{n - 1} - 1\). There are \(n^2\) discrete actions in total.
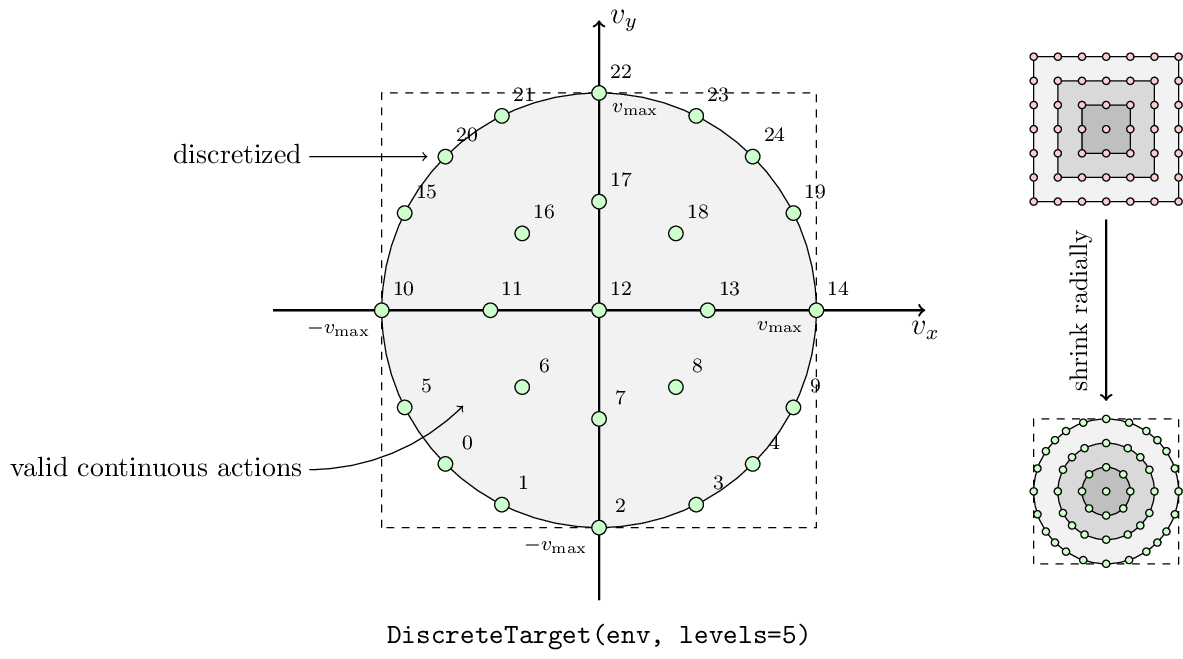
Discretization rule for targets:
where \(i, j \in \{0, 1, \dots, n - 1\}\), and \(\xi = \frac{2 i}{n - 1} - 1\), and \(\eta = \frac{2 j}{n - 1} - 1\). There are \(n^2\) discrete actions in total.
Note
In the environment, the abilities of different agents may be different. For example, the faster target’s step size \(v_{\max}\) is larger than the slower one. But after the discretization, the same discrete actions are different for different agents. The \(0\)-th action for all targets is to move to the southwest, but different targets have different step sizes. This discretization operation not only loses the flexibility of continuous control but also drops the information about abilities for different agents. The first problem can be alleviated by increasing the discretization level. For the second issue, some information of the agent’s abilities has been encoded in the private state and the observation (see States and Observations).
Single-Team Multi-Agent Setting
Wrapper for the multi-camera environment (need to provide an instance of target agent as part of the environment):
base_env = mate.make('MultiAgentTracking-v0')
# base_env = mate.DiscreteCamera(base_env, levels=5) # uncomment for discrete setting
env = mate.MultiCamera(base_env, target_agent=TargetAgent(seed=0))
env.seed(0)
camera_joint_observation = env.reset()
camera_joint_action = env.action_space.sample() # your agent here (this takes random actions)
camera_joint_observation, camera_team_reward, done, camera_infos = env.step(camera_joint_action)
Wrapper for the multi-target environment (need to provide an instance of camera agent as part of the environment):
base_env = mate.make('MultiAgentTracking-v0')
# base_env = mate.DiscreteTarget(base_env, levels=5) # uncomment for discrete setting
env = mate.MultiTarget(base_env, camera_agent=CameraAgent(seed=0))
env.seed(0)
target_joint_observation = env.reset()
target_joint_action = env.action_space.sample() # your agent here (this takes random actions)
target_joint_observation, target_team_reward, done, target_infos = env.step(target_joint_action)
Note
The wrapper will use agent.spawn(num_agents) to generate multiple new agents, that is, call agent.clone() several times.
By default, the behavior of agent.clone() is copy.deepcopy(agent).
You can override this in your own agent classes.
Single-Team Single-Agent Setting
Wrapper for the single-camera environment (need to provide a camera agent instance and a target agent instance as part of the environment):
base_env = mate.make('MultiAgentTracking-v0')
# base_env = mate.DiscreteCamera(base_env, levels=5) # uncomment for discrete setting
env = mate.SingleCamera(base_env, other_camera_agent=CameraAgent(seed=0),
target_agent=TargetAgent(seed=0))
env.seed(0)
camera_observation = env.reset()
camera_action = env.action_space.sample() # your agent here (this takes random actions)
camera_observation, camera_reward, done, camera_info = env.step(camera_action)
Wrapper for the single-target environment (need to provide a target agent instance and a camera agent instance as part of the environment):
base_env = mate.make('MultiAgentTracking-v0')
# base_env = mate.DiscreteTarget(base_env, levels=5) # uncomment for discrete setting
env = mate.SingleTarget(base_env, other_target_agent=TargetAgent(seed=0),
camera_agent=CameraAgent(seed=0))
env.seed(0)
target_observation = env.reset()
target_action = env.action_space.sample() # your agent here (this takes random actions)
target_observation, target_reward, done, target_info = env.step(target_action)
Note
The wrapper will use agent.spawn(num_agents) to generate multiple new agents, that is, call agent.clone() several times.
By default, the behavior of agent.clone() is copy.deepcopy(agent).
You can override this in your own agent classes.
Auxiliary Camera Rewards
A wrapper that adds additional auxiliary rewards for each individual camera. (Not used in the evaluation script.)
The auxiliary reward is a weighted sum of the following components:
raw_reward(the higher the better): team reward returned by the environment (shared, range in \((-\infty, 0]\)).
coverage_rate(the higher the better): coverage rate of all targets in the environment (shared, range in \([0, 1]\)).
real_coverage_rate(the higher the better): coverage rate of targets with cargoes in the environment (shared, range in \([0, 1]\)).
mean_transport_rate(the lower the better): mean transport rate of the target team (shared, range in \([0, 1]\)).
soft_coverage_score(the higher the better): soft coverage score is proportional to the distance from the target to the camera’s boundary (individual, range in \([-1, N_{\mathcal{T}}]\)).
num_tracked(the higher the better): number of targets tracked the camera (shared, range in \([0, N_{\mathcal{T}}]\)).
baseline: constant \(1\).
base_env = mate.make('MultiAgentTracking-v0')
env = mate.MultiCamera(base_env, target_agent=mate.GreedyTargetAgent(seed=0))
env = mate.RepeatedRewardIndividualDone(env)
env = mate.AuxiliaryCameraRewards(env, coefficients={'raw_reward': 1.0,
'coverage_rate': 1.0,
'soft_coverage_score': 1.0,
'baseline': -2.0},
reduction='mean') # average all individual rewards as shared team reward
This wrapper adds a dense reward for each individual camera, which provides timely feedback to the agents regarding the desirability of their actions. It can accelerate the training of RL camera agents in the environment.
Note
The soft coverage score is proportional to the distance from the target to the camera’s boundary. The score is normalized with the maximum distance (from the camera’s incenter to the boundary).
Auxiliary Target Rewards
A wrapper that adds additional auxiliary rewards for each individual target. (Not used in the evaluation script.)
The auxiliary reward is a weighted sum of the following components:
raw_reward(the higher the better): team reward returned by the environment (shared, range in \([0, +\infty)\)).
coverage_rate(the lower the better): coverage rate of all targets in the environment (shared, range in \([0, 1]\)).
real_coverage_rate(the lower the better): coverage rate of targets with cargoes in the environment (shared, range in \([0, 1]\)).
mean_transport_rate(the higher the better): mean transport rate of the target team (shared, range in \([0, 1]\)).
normalized_goal_distance(the lower the better): the normalized value of the distance to destination, or the nearest non-empty warehouse when the target is not loaded (individual, range in \([0, \sqrt{2}]\)).
sparse_delivery(the higher the better): a boolean value that indicates whether the target reaches the destination (individual, range in \({0, 1}\)).
soft_coverage_score(the lower the better): soft coverage score is proportional to the distance from the target to the camera’s boundary (individual, range in \([-1, N_{\mathcal{C}}]\)).
is_tracked(the lower the better): a boolean value that indicates whether the target is tracked by any camera or not. (individual, range in \({0, 1}\)).
is_colliding(the lower the better): a boolean value that indicates whether the target is colliding with obstacles, cameras’ barriers of terrain boundary. (individual, range in \({0, 1}\)).
baseline: constant \(1\).
base_env = mate.make('MultiAgentTracking-v0')
env = mate.MultiTarget(base_env, camera_agent=mate.GreedyCameraAgent(seed=0))
env = mate.RepeatedRewardIndividualDone(env)
env = mate.AuxiliaryTargetRewards(env, coefficients={'raw_reward': 1.0,
'real_coverage_rate': -1.0,
'normalized_goal_distance': -1.0,
'sparse_delivery': 100.0,
'soft_coverage_score': -1.0},
reduction='none') # individual reward
This wrapper adds a dense reward for each individual target, which provides timely feedback to the agents regarding the desirability of their actions. It can accelerate the training of RL target agents in the environment.
Note
The soft coverage score is proportional to the distance from the target to the camera’s boundary. The score is normalized with the maximum distance (from the camera’s incenter to the boundary).
Message Filter
A wrapper that filters messages from agents of intra-team communications. (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
# The `filter` argument should be a function with signature: (env, message) -> bool
filter_both = mate.MessageFilter(base_env, filter=func)
filter_camera = mate.MessageFilter(mate.MultiCamera(base_env, ...), filter=func)
filter_target = mate.MessageFilter(mate.MultiTarget(base_env, ...), filter=func)
This wrapper can be applied multiple times with different filter functions.
Hint
The filter function can also modify the message content. Users can use this to add channel signal noises etc.
Users can use this wrapper to implement a communication channel with limited bandwidth, limited communication range, or random dropout. For example:
base_env = mate.make('MultiAgentTracking-v0')
dropout_rate = 0.1
dropout_both = mate.MessageFilter(base_env, filter=lambda env, message: not env.np_random.binomial(1, dropout_rate))
Random Message Dropout
A wrapper that randomly drops messages in communication channels. (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
dropout_both = mate.RandomMessageDropout(base_env, dropout_rate=0.1)
dropout_camera = mate.RandomMessageDropout(mate.MultiCamera(base_env, ...), dropout_rate=0.1)
dropout_target = mate.RandomMessageDropout(mate.MultiTarget(base_env, ...), dropout_rate=0.1)
Restricted Communication Range
A wrapper that adds a restricted communication range to channels. (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
env = mate.RestrictedCommunicationRange(base_env, range_limit=mate.TERRAIN_WIDTH / 3.0)
No Communication
A wrapper that disables intra-team communications, i.e., filters out all messages.
base_env = mate.make('MultiAgentTracking-v0')
disable_both = mate.NoCommunication(base_env)
disable_both = mate.NoCommunication(base_env, team='both')
disable_camera = mate.NoCommunication(base_env, team='camera')
disable_camera = mate.NoCommunication(mate.MultiCamera(base_env, ...))
disable_target = mate.NoCommunication(base_env, team='target')
disable_target = mate.NoCommunication(mate.MultiTarget(base_env, ...))
Extra Communication Delays
A wrapper that adds extra message delays to communication channels. (Not used in the evaluation script.)
base_env = mate.make('MultiAgentTracking-v0')
# The `delay` argument should be a function with signature: (env, message) -> int
# or a constant positive integer.
delay_both = mate.ExtraCommunicationDelays(base_env, delay=lambda env, message: env.np_random.randint(5)) # random delay
delay_camera = mate.ExtraCommunicationDelays(mate.MultiCamera(base_env, ...), delay=3) # constant delay
delay_target = mate.ExtraCommunicationDelays(mate.MultiTarget(base_env, ...), delay=3)
Users can use this wrapper to implement a communication channel with random delays.
Render Communication
A wrapper that draws arrows for intra-team communications in rendering results.
base_env = mate.make('MultiAgentTracking-v0')
base_env = mate.RenderCommunication(base_env)
- Related Resources